7. Approximating time series¶
Raw time series can be noisy or have a lot of time points. Approximating them
can be useful so that the most important information is kept while reducing
noise. The pyts.approximation module provides simple tools for
approximating time series.
7.1. Piecewise Aggregate Approximation¶
PiecewiseAggregateApproximation (PAA) reduces the number of time points
of a time series using a sliding window and taking the mean value in this
window. It transforms a time series  into another
time series
into another
time series  with
with
 such that, if
such that, if  divides
divides  , then
, then

If does not divides , two options are made available with
the overlapping parameter:
- If
overlapping=True, the length of the sliding window is constant and some windows are overlapping. - If
overlapping=False, the length of the sliding window may vary and the windows are non-overlapping.
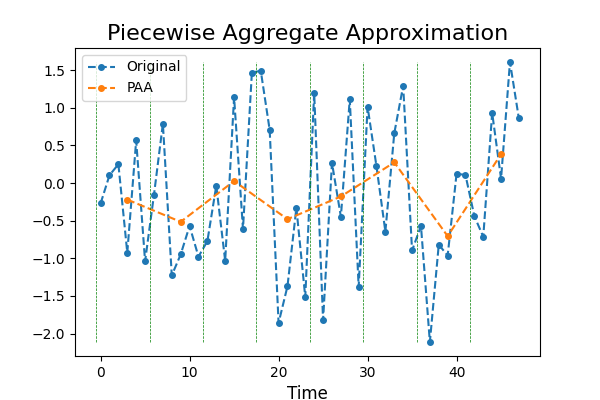
>>> from pyts.approximation import PiecewiseAggregateApproximation
>>> X = [[0, 4, 2, 1, 7, 6, 3, 5],
... [2, 5, 4, 5, 3, 4, 2, 3]]
>>> transformer = PiecewiseAggregateApproximation(window_size=2)
>>> transformer.transform(X)
array([[2. , 1.5, 6.5, 4. ],
[3.5, 4.5, 3.5, 2.5]])
References
- E. Keogh, K. Chakrabarti, M. Pazzani, and S. Mehrotra, “Dimensionality reduction for fast similarity search in large time series databases”. Knowledge and information Systems, 3(3), 263-286 (2001).
7.2. Symbolic Aggregate approXimation¶
SymbolicAggregateApproximation (SAX) reduces the dimension of
the feature space by discretizing each time series independently. Several
strategies can be used to derive the edges of the bins with the strategy
parameter:
strategy='uniform': all bins in each sample have identical widths,strategy='quantile': all bins in each sample have the same number of points,strategy='normal': bin edges are quantiles from a standard normal distribution.
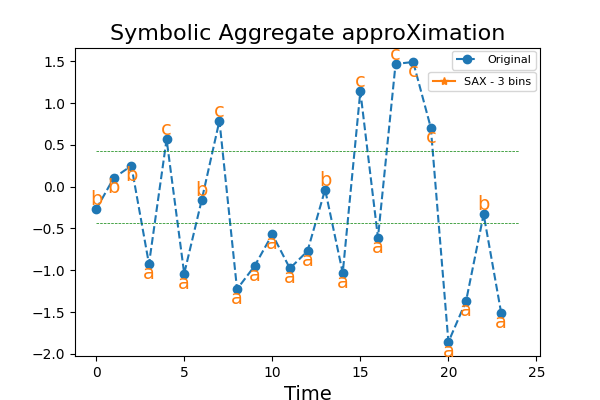
>>> from pyts.approximation import SymbolicAggregateApproximation
>>> X = [[0, 4, 2, 1, 7, 6, 3, 5],
... [2, 5, 4, 5, 3, 4, 2, 3]]
>>> transformer = SymbolicAggregateApproximation()
>>> print(transformer.transform(X))
[['a' 'c' 'b' 'a' 'd' 'd' 'b' 'c']
['a' 'd' 'c' 'd' 'b' 'c' 'a' 'b']]
References
- J. Lin, E. Keogh, L. Wei, and S. Lonardi, “Experiencing SAX: a novel symbolic representation of time series”. Data Mining and Knowledge Discovery, 15(2), 107-144 (2007).
7.3. Discrete Fourier Transform¶
DiscreteFourierTransform extracts Fourier coefficients from each
time series. The n_coefs parameter controls the number of Fourier
coefficients to keep.
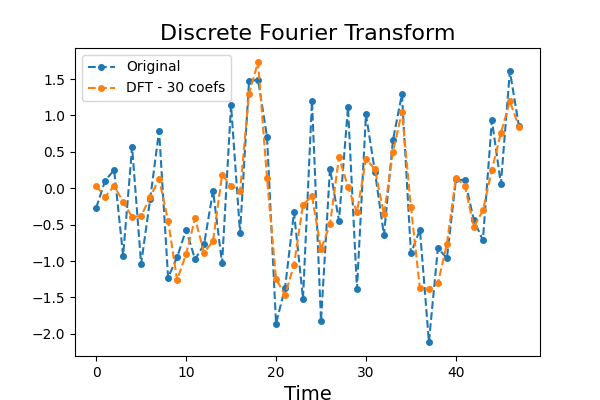
>>> from pyts.approximation import DiscreteFourierTransform
>>> from pyts.datasets import load_gunpoint
>>> X, _, _, _ = load_gunpoint(return_X_y=True)
>>> transformer = DiscreteFourierTransform(n_coefs=4)
>>> X_new = transformer.fit_transform(X)
>>> X_new.shape
(50, 4)
References
- P. Schäfer, and M. Högqvist, “SFA: A Symbolic Fourier Approximation and Index for Similarity Search in High Dimensional Datasets”, International Conference on Extending Database Technology, 15, 516-527 (2012).
7.4. Multiple Coefficient Binning¶
MultipleCoefficientBinning is similar to Symbolic Aggregate approXimation,
but it discretizes each time point independently. Therefore, it is very close
to sklearn.prepreocessing.KBinsDiscretizer
but the strategy parameter can take different values:
- ‘uniform’: all bins in each sample have identical widths,
- ‘quantile’: all bins in each sample have the same number of points,
- ‘normal’: bin edges are quantiles from a standard normal distribution,
- ‘entropy’: bin edges are computed using information gain.
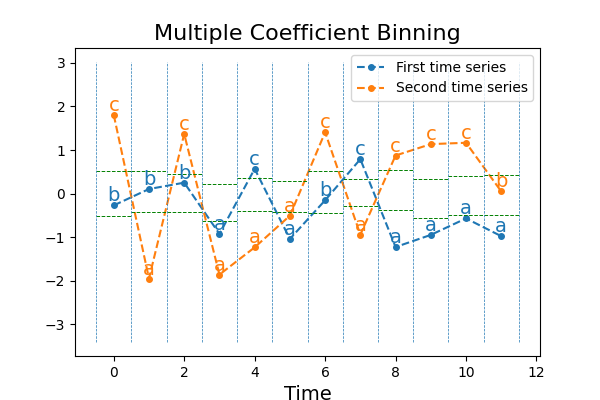
>>> from pyts.approximation import MultipleCoefficientBinning
>>> X = [[0, 4],
... [2, 7],
... [1, 6],
... [3, 5]]
>>> transformer = MultipleCoefficientBinning(n_bins=2)
>>> print(transformer.fit_transform(X))
[['a' 'a']
['b' 'b']
['a' 'b']
['b' 'a']]
References
- P. Schäfer, and M. Högqvist, “SFA: A Symbolic Fourier Approximation and Index for Similarity Search in High Dimensional Datasets”, International Conference on Extending Database Technology, 15, 516-527 (2012).
7.5. Symbolic Fourier Approximation¶
SymbolicFourierApproximation consists in combining
Discrete Fourier Transform and Multiple Coefficient Binning:
- First Fourier coefficients are derived using
DiscreteFourierTransform, - Then Fourier coefficients are discretized using
MultipleCoefficientBinning.
References
- P. Schäfer, and M. Högqvist, “SFA: A Symbolic Fourier Approximation and Index for Similarity Search in High Dimensional Datasets”, International Conference on Extending Database Technology, 15, 516-527 (2012)
