5. Preprocessing utilities¶
Preprocessing is an important step in most machine learning pipelines.
Contrary to standard machine learning, where each feature is independently
preprocessed, each time series is independently preprocessed. We modify
most preprocessing tools from scikit-learn accordingly for time series.
These tools can be found in the pyts.prepocessing module.
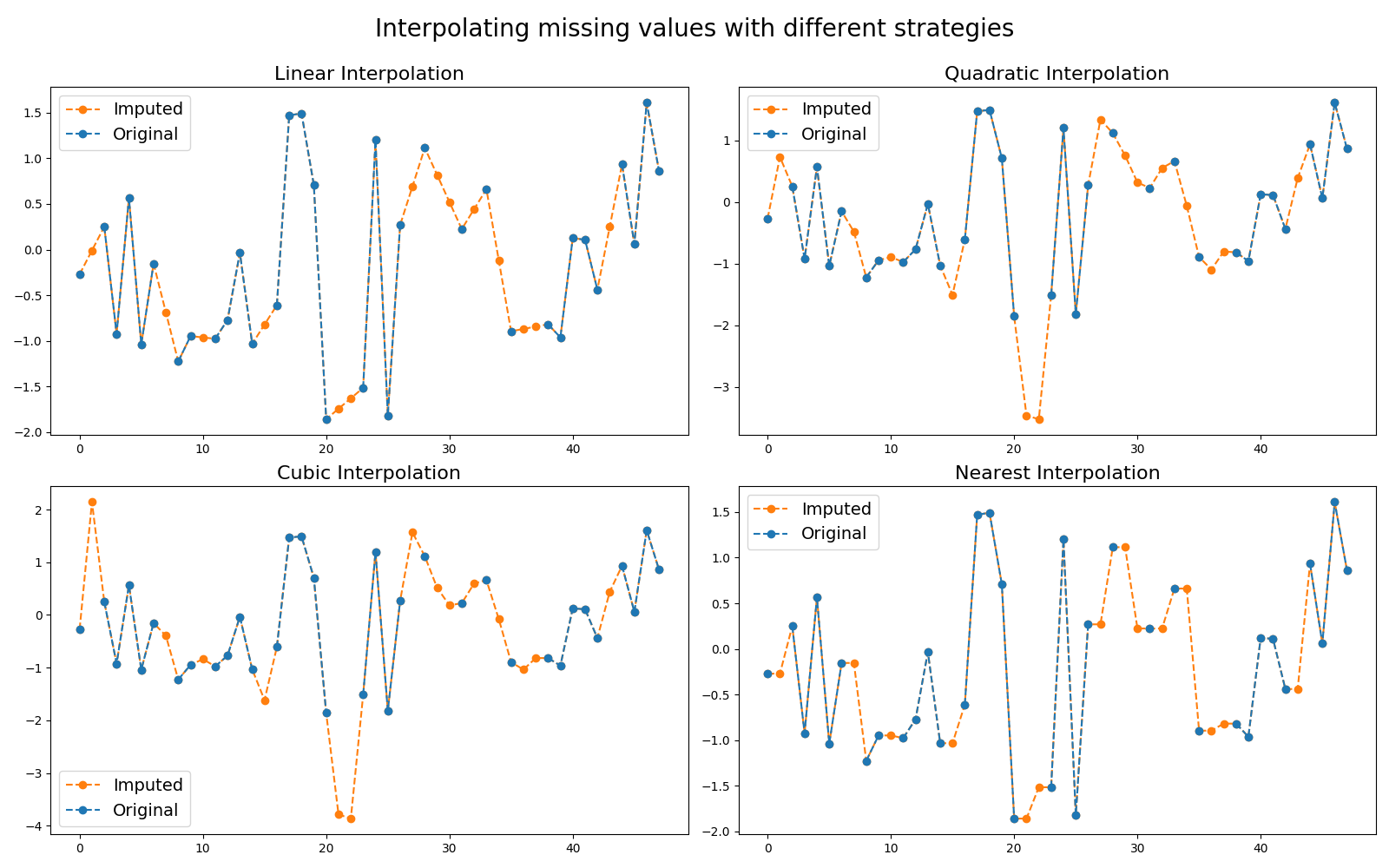
5.1. Imputing missing values¶
InterpolationImputer imputes missing values for each time series
independently using the
scipy.interpolate.interp1d
function. The strategy parameter controls the strategy used to perform the
interpolation. The following example illustrates the impact of this parameter
on the imputed values.
>>> import numpy as np
>>> from pyts.preprocessing import InterpolationImputer
>>> X = [[1, None, 3, 4], [8, None, 4, None]]
>>> imputer = InterpolationImputer()
>>> imputer.transform(X)
array([[1., 2., 3., 4.],
[8., 6., 4., 2.]])
>>> imputer.set_params(strategy='previous')
>>> imputer.transform(X)
array([[1., 1., 3., 4.],
[8., 8., 4., 4.]])
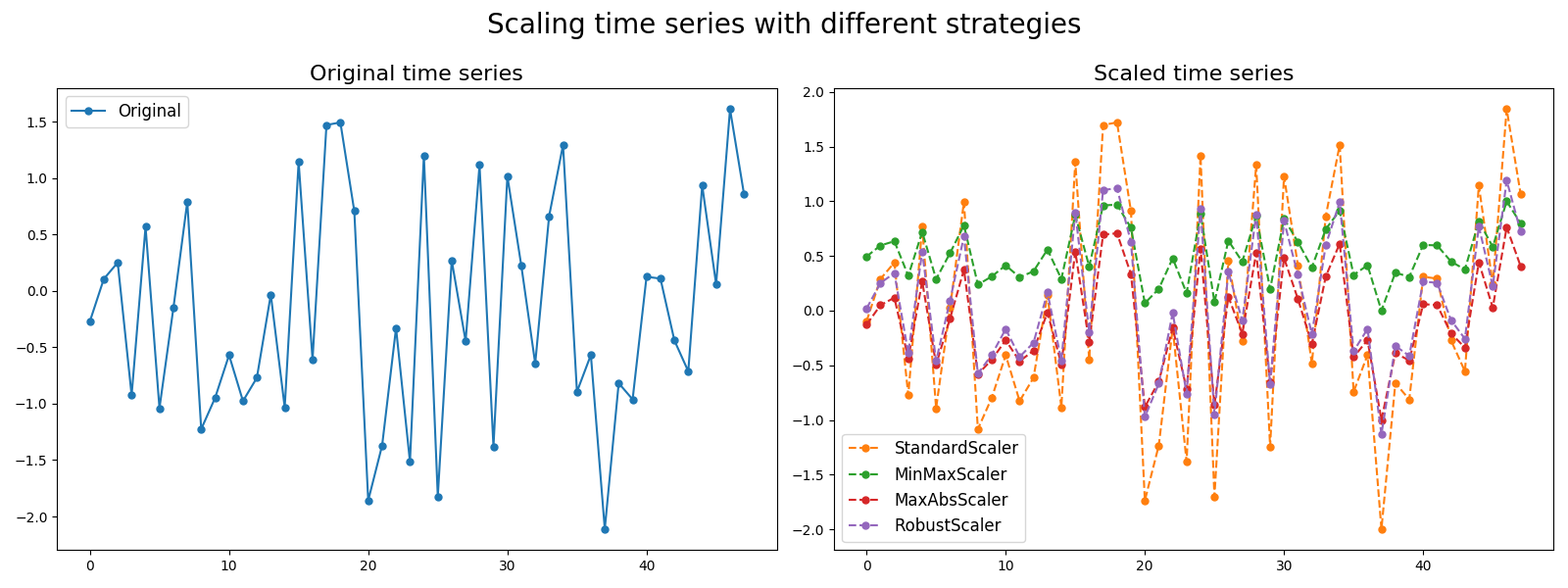
5.2. Scaling¶
Scaling consists in transforming linearly a time series. Several scaling tools are made available:
StandardScaler: each time series has zero mean and unit variance,MinMaxScaler: each time series is scaled in a given range,MaxAbsScaler: each time series is scaled by its maximum absolute value,RobustScaler: each time series is scaled using statistics that are robust to outliers.
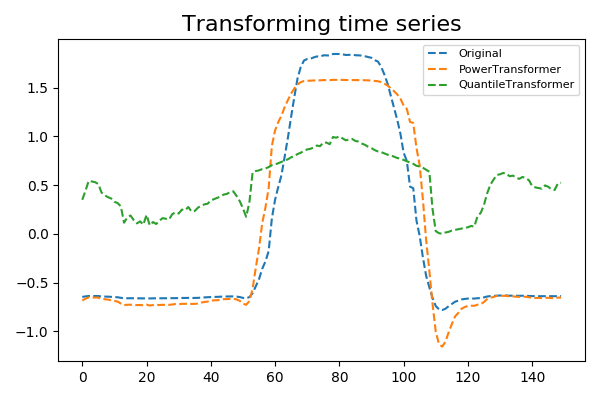
5.3. Non-linear transformation¶
Some algorithms make assumptions on the distribution of the data. Therefore it can be useful to transform time series so that they approximatively follow a given distribution. Two tools are made available:
PowerTransformer: each time series is transformed to be more Gaussian-like,QuantileTransformer: each time series is transformed using quantile information.