2. Classification of raw time series¶
Algorithms that can directly classify time series have been developed.
The following sections will describe the ones that are available in pyts.
They can be found in the pyts.classification module.
2.1. KNeighborsClassifier¶
The k-nearest neighbors algorithm is a relatively simple algorithm.
KNeighborsClassifier finds the k nearest neighbors of a time series
and the predicted class is determined with majority voting. A key parameter
of this algorithm is the metric used to find the nearest neighbors.
A popular metric for time series is the Dynamic Time Warping metric
(see Metrics for time series).
The one-nearest-neighbor algorithm with this metric can be considered as
a good baseline for time series classification:
>>> from pyts.classification import KNeighborsClassifier
>>> from pyts.datasets import load_gunpoint
>>> X_train, X_test, y_train, y_test = load_gunpoint(return_X_y=True)
>>> clf = KNeighborsClassifier(metric='dtw')
>>> clf.fit(X_train, y_train)
KNeighborsClassifier(...)
>>> clf.score(X_test, y_test)
0.91...
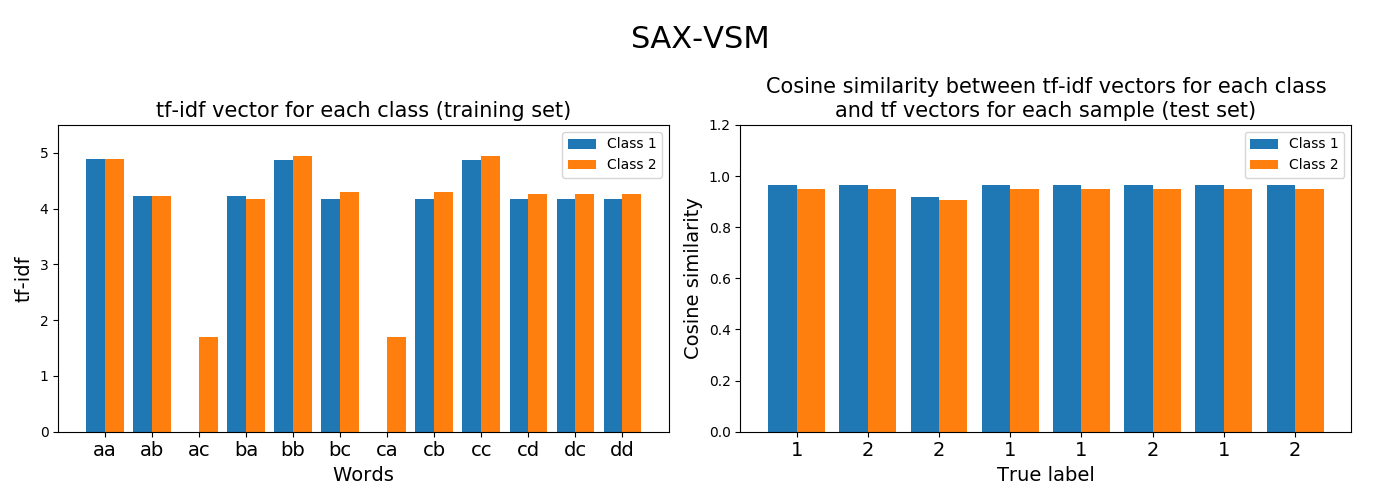
2.2. SAX-VSM¶
SAX-VSM stands for Symbolic Aggregate approXimation in
Vector Space Model.
SAXVSM is an algorithm based on the SAX representation of time
series in a vector space model. It first transforms a time series of floats
into a sequence of letters using the Symbolic Aggregate approXimation algorithm.
Then each sequence of letters is transformed into a bag of words using a sliding
window. Finally, a term-frequency inverse-term-frequency (tf-idf) vector is computed
for each class. Predictions are made using the cosine similarity between
the time series and the tf-idf vectors for each class. The predicted class
is the class yielding the highest cosine similarity.
>>> from pyts.classification import SAXVSM
>>> from pyts.datasets import load_gunpoint
>>> X_train, X_test, y_train, y_test = load_gunpoint(return_X_y=True)
>>> clf = SAXVSM(window_size=34, sublinear_tf=False, use_idf=False)
>>> clf.fit(X_train, y_train)
SAXVSM(...)
>>> clf.score(X_test, y_test)
0.76
References
- P. Senin, and S. Malinchik, “SAX-VSM: Interpretable Time Series Classification Using SAX and Vector Space Model”. International Conference on Data Mining, 13, 1175-1180 (2013).
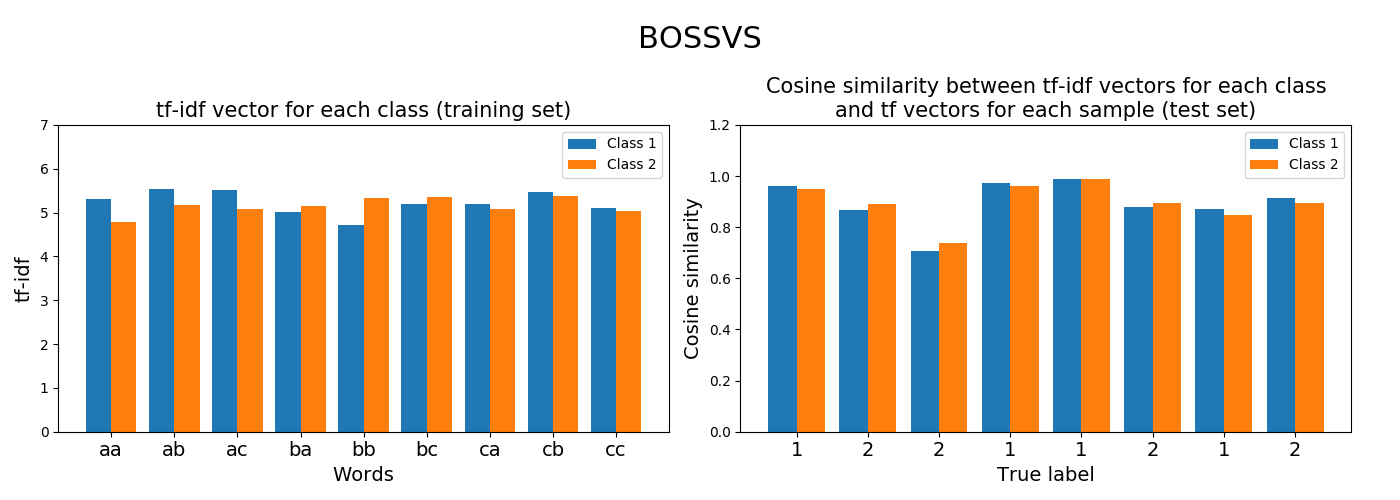
2.3. BOSSVS¶
BOSSVS stands for Bag of Symbolic Fourier Symbols in
Vector Space.
BOSSVS is another bag-of-words approach for time series classification.
BOSSVS is relatively similar to SAX-VSM: it builds a term-frequency
inverse-term-frequency vector for each class, but the symbols used to create
the words are generated with the Symbolic Fourier Approximation algorithm.
>>> from pyts.classification import BOSSVS
>>> from pyts.datasets import load_gunpoint
>>> X_train, X_test, y_train, y_test = load_gunpoint(return_X_y=True)
>>> clf = BOSSVS(window_size=28)
>>> clf.fit(X_train, y_train)
BOSSVS(...)
>>> clf.score(X_test, y_test)
0.98
References
- P. Schäfer, “Scalable Time Series Classification”. Data Mining and Knowledge Discovery, 30(5), 1273-1298 (2016).
