8. Bag of words for time series¶
Several algorithms for time series classification are based on bag-of-words
approaches: a sequence of symbols is transformed into a bag of words.
Utilities to derive bag of words are provided in the pyts.bag_of_words
module.
8.1. Bag of words¶
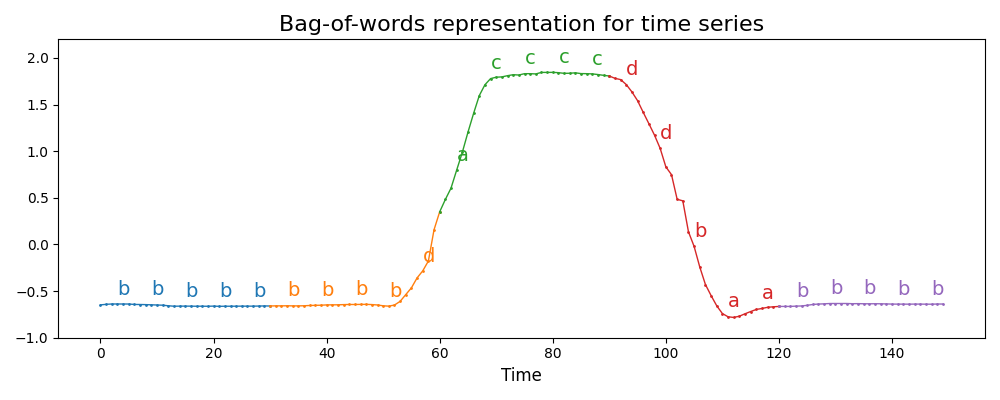
BagOfWords extracts subseries using a sliding window, then transforms
each subseries into a word using the Piecewise Aggregate Approximation and
Symbolic Aggregate approXimation algorithms. Therefore BagOfWords trasnforms
each time series into a bag of words. The sliding window can be controlled
with the window_size and window_step parameters. The length of
each word can be set with the word_size parameter, while the n_bins
parameter controls the size of the alphabet to discretize time series.
The numerosity_reduction parameter controls the removal of all but one
occurrence of identical consecutive words.
>>> import numpy as np
>>> from pyts.bag_of_words import BagOfWords
>>> X = np.arange(12).reshape(2, 6)
>>> bow = BagOfWords(window_size=4, word_size=4)
>>> bow.transform(X)
array(['abcd', 'abcd'], dtype='<U4')
>>> bow.set_params(numerosity_reduction=False)
BagOfWords(...)
>>> bow.transform(X)
array(['abcd abcd abcd', 'abcd abcd abcd'], dtype='<U14')
8.2. Word Extractor¶
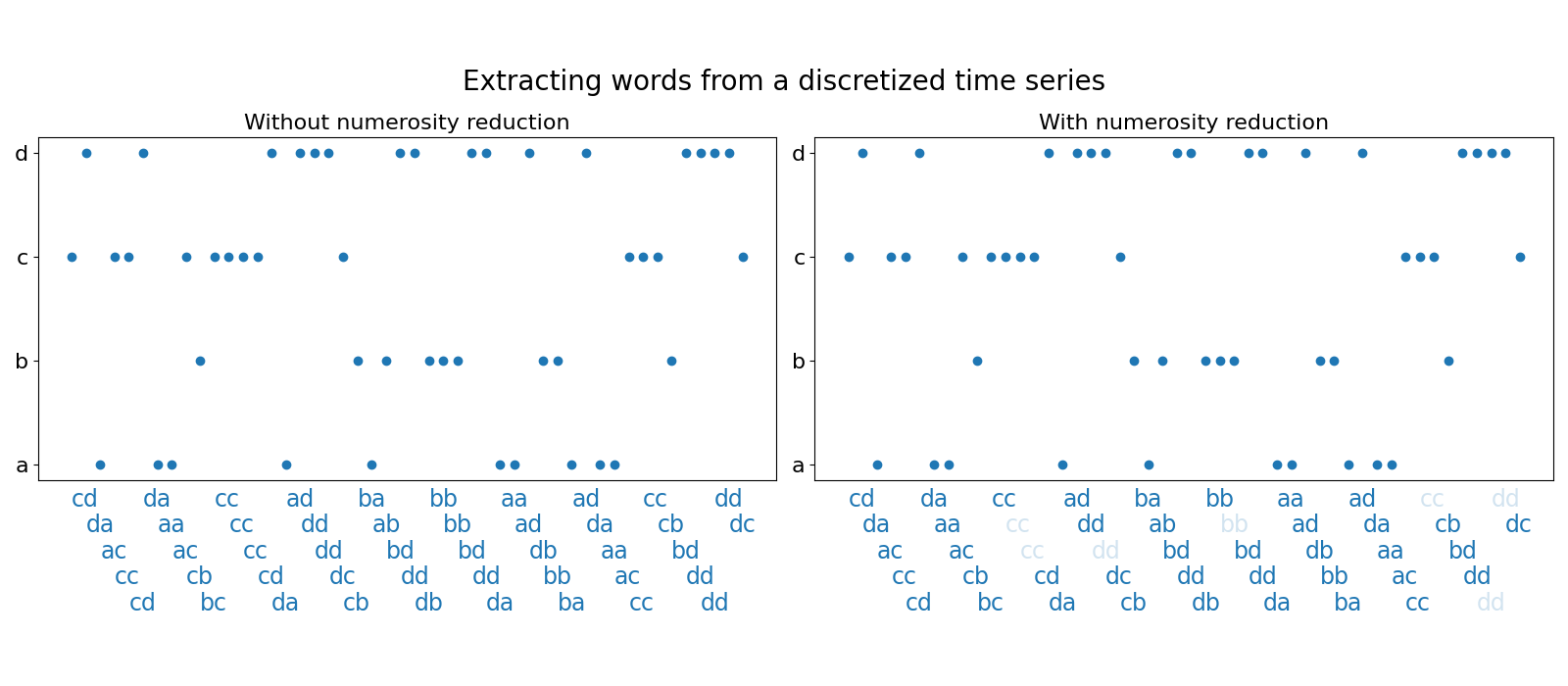
WordExtractor extracts words from a sequence of symbols. This sequence
of symbols is usually a discretized time series or discretized Fourier
coefficients of a time series. Words are extracted using a sliding window
that can be controlled with the window_size and window_step parameters.
The numerosity_reduction parameter controls the removal of all but one
occurrence of identical consecutive words. The impact of this parameter is illustrated
in the following example: when a time series has low variation over several
time points, the discretized time series is constant, which leads to several
identical consecutive words. Removed words are almost transparent.
>>> from pyts.bag_of_words import WordExtractor
>>> X = [['a', 'a', 'b', 'a', 'b', 'b', 'b', 'b', 'a'],
... ['a', 'b', 'c', 'c', 'c', 'c', 'a', 'a', 'c']]
>>> word = WordExtractor(window_size=2)
>>> print(word.transform(X))
['aa ab ba ab bb ba' 'ab bc cc ca aa ac']
>>> word = WordExtractor(window_size=2, numerosity_reduction=False)
>>> print(word.transform(X))
['aa ab ba ab bb bb bb ba' 'ab bc cc cc cc ca aa ac']
